The other day we noticed some odd behavior from some blades in a somewhat large environment. The environment is a mix of B200 M3 and B440 M2 blades. The oddity was random and intermittent disconnections from storage and/or full unresponsiveness in vCenter. Something that caught my eye was the fact that it was specific to the B440 blades in the environment. In all actuality, it was spread between multiple sites as well which lead us to believe that it was related to ESXi or the B440 blades. We ruled out anything with storage and networking because the effects would be more widespread if that were the case.
Me being the VMware guy, I proceeded to look at it from my side of the fence. Jumping into the logs I found a numerous amount of odd errors on the B440 blades in the vmkernel.log. Here is a snippet of those errors:
2013-12-31T16:09:24.561Z cpu70:33819)WARNING: LinDMA: Linux_DMACheckConstraints:138: Cannot map machine address = 0x1007c1bacc2, length = 9018 for device 0000:06:00.0; reason = address exceeds dma_mask (0xffffffffff))
That error was repeated hundreds, even thousands of times. You would also notice that somewhere in that log you would see an All Paths Down (APD) error. This was due to the fact that the NFS vmkernel interface was one of the interfaces on the Cisco VIC that was being affected by this. We were able to track this down to the following:
000:06:00.0 Network controller: Cisco Systems Inc Cisco VIC Ethernet NIC [vmnic2] 0000:07:00.0 Network controller: Cisco Systems Inc Cisco VIC Ethernet NIC [vmnic3]
Armed with this information, we jumped into the UCS configuration to tie some things together. When we look in UCSM at one of the B440 blades you will see the VIC 1280 providing 2 cards. vmnic2 and vmnic3 were both placed on card 2. So we know from that information and verification that it is specific to the second card presented from the VIC 1280. We checked firmware levels for UCS and the blades and driver versions for enic/fnic. We were running firmware version 2.1(3a) and the latest enic/fnic drivers at the time that we knew of, verified by VMware as well on the enic/fnic driver versions. You can verify your versions of the enic and fnic drivers by logging into the hosts console via ssh and running the following commands:
~# vmkload_mod -s enic
~# vmkload_mod -s fnic
That will provide you with the module output, and will look something like this:
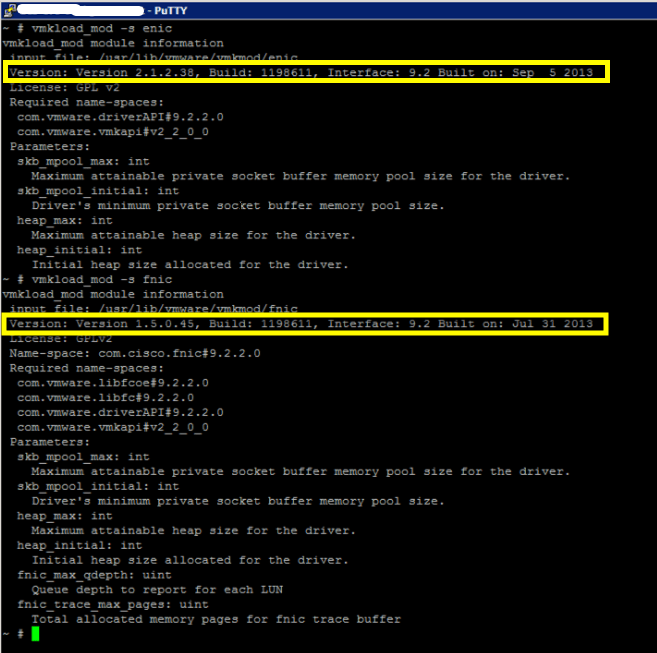
And by looking at the Dynamic Memory Allocation (DMA) error we are receiving we saw that we were running into this Cisco Bug:
https://tools.cisco.com/bugsearch/bug/CSCuf73395 (CCO login required)
The fix for this was to update the firmware to 2.2 and update the enic/fnic drivers on the ESXi hosts to 2.1.2.42 and 1.6.0.5, respectively. I hope this saves someone some time as this took quite a bit of troubleshooting from all sides. If this helped you out, let us know in the comments below!
